Workshop on Toxic Language Detection (TLD)
The first Workshop on Toxic Language Detection (TLD) will be held in conjunction with the 35th Australasian Joint Conference on Artificial Intelligence (AJCAI 2022) in Perth, Western Australia.
- Workshop date & time : 6 Dec 2022 (11AM - 4PM, Australian Western Standard Time (AWST / UTC+8)).
- Workshop physical location : Hyatt Regency Perth
- Hybrid mode : Go to Teams
Overview

The growth of online content presents challenges to detect toxic language using Natural Language Processing (NLP). Fast detection of such language can enable mitigation strategies to be acted to thwart toxic situations. In this workshop, we use toxic language as a broader concept that can be overlapped with other terms such as abusive language, hate speech, or offensive language. The goal of the workshop is to bring together researchers and practitioners to engage in a discussion about identifying and detecting such toxic language. The workshop consists of
- a series of invited talks by reputed members of the NLP community on toxicity detection from academia related to the topics below;
- a shared task with leaderboard challenges for CONDA in-game toxicity dataset; and
- a presentation and ceremony for the leaderboard challenges.
Topics of interest include, but are not limited to:
- NLP Models for Toxic Language Detection across different domains (e.g. social media, news comments, Wikipedia, and in-game chat).
- Multi-modal Models for Toxic Language Detection (e.g. A combination of using text, audio, and image).
- Development of Low Resource Language for Toxicity Detection.
- Multi-lingual Dataset and Models for Toxic Language Detection.
- Applications of Toxic Language Detection.
- Human-Computer Interaction for Toxic Language Detection System.
- Bias in Toxic Language Detection Systems.
Invited Speakers
The invited speakers from around the world are follows. (order by program schedule, Name links to a personal webpage or a google scholar.)
| Speaker | Topic |
|---|---|
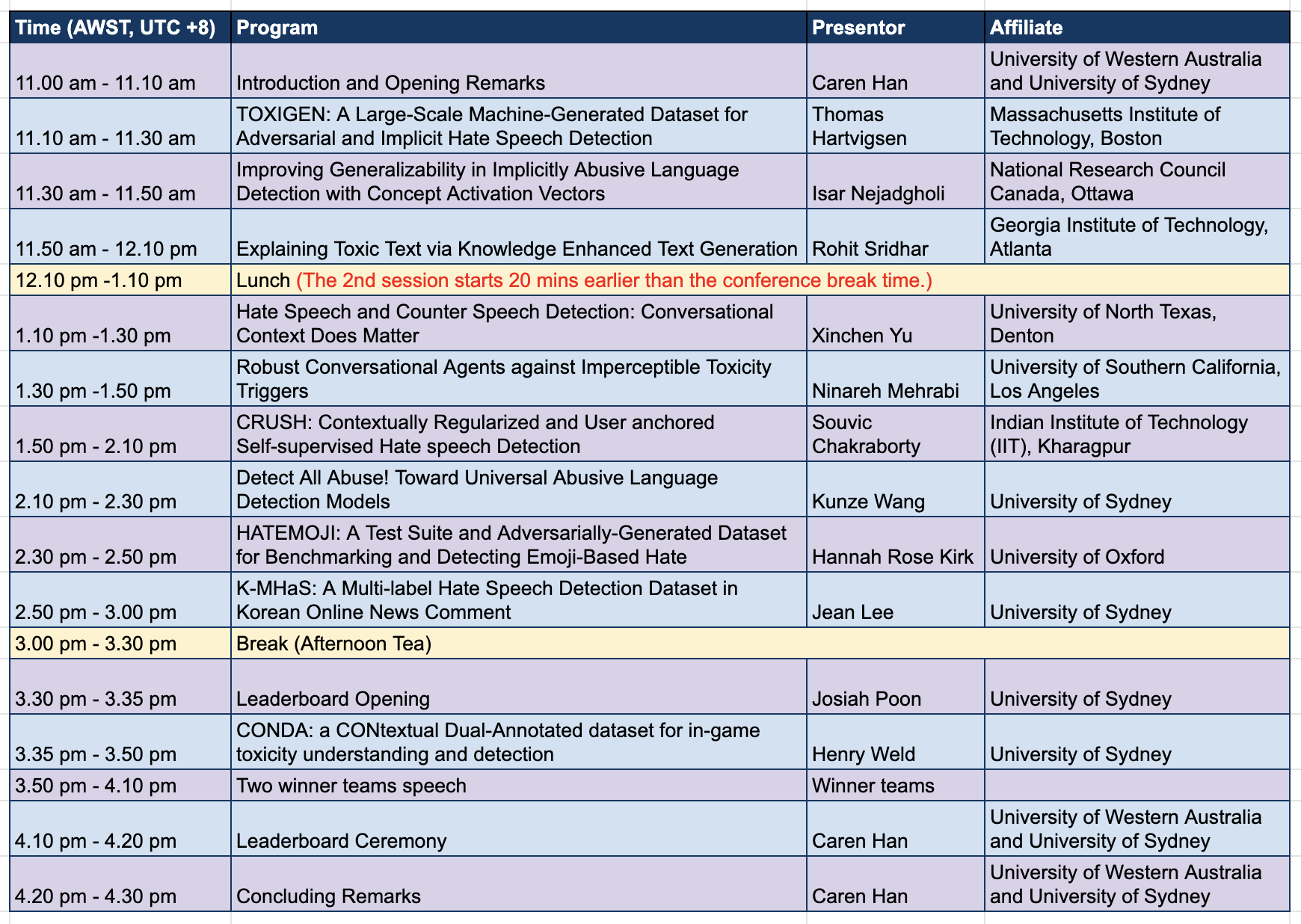
| Dr. Thomas Hartvigsen(Massachusetts Institute of Technology) | ToxiGen: A Large-Scale Machine-Generated Dataset for Adversarial and Implicit Hate Speech Detection (Publication @ ACL 2022) |
| Dr. Isar Nejadgholi(National Research Council Canada) | Improving Generalizability in Implicitly Abusive Language Detection with Concept Activation Vectors (Publication @ ACL 2022) |
| Mr. Rohit Sridhar(Georgia Institute of Technology) | Explaining Toxic Text via Knowledge Enhanced Text Generation (Publication @ NAACL 2022) |
| Miss Xinchen Yu(University of North Texas) | Hate Speech and Counter Speech Detection: Conversational Context Does Matter (Publication @ NAACL 2022) |
| Dr. Ninareh Mehrabi(University of Southern California) | Robust Conversational Agents against Imperceptible Toxicity Triggers (Publication @ NAACL 2022) |
| Mr. Souvic Chakraborty(Indian Institute of Technology (IIT)) | CRUSH: Contextually Regularized and User anchored Self-supervised Hate speech Detection (Publication @ NAACL 2022) |
| Mr. Kunze Wang(University of Sydney) | Detect All Abuse! Toward Universal Abusive Language Detection Models (Publication @ COLING 2020) |
| Ms. Hannah Rose Kirk(University of Oxford) | HATEMOJI: A Test Suite and Adversarially-Generated Dataset for Benchmarking and Detecting Emoji-Based Hate (Publication @ NAACL 2022) |
| Ms. Jean Lee(University of Sydney) | K-MHaS: A Multi-label Hate Speech Detection Dataset in Korean Online News Comment (Publication @ COLING 2022) |
| Dr. Henry Weld(University of Sydney) | CONDA: a CONtextual Dual-Annotated dataset for in-game toxicity understanding and detection (Publication @ ACL 2021) |
Program Schedule
Leaderboard Challenge
To promote the research and practice, a shared task for CONDA Toxicity Detection Challenge will be held in November 2022, and two winning team will be awarded a cash prize. This competition will provide a good testbed for participants to develop better toxicity detection systems.
CONDA: a CONtextual Dual-Annotated dataset for in-game toxicity understanding and detection.
Accepted by ACL-IJCNLP 2021.
Paper | Presentation | Github
Traditional toxicity detection models have focused on the single utterance level without deeper understanding of context. The CONDA dataset is to detect in-game toxic language, enabling joint intent classification and slot filling analysis, which is a core task in Natural Language Understanding (NLU). The dataset consists of 45K utterances from 12K conversations from the chat logs of 1.9K completed the Defense of the Ancients 2 (Dota 2) matches. Dota 2 is a multiplayer online game where teams of five players attempt to destroy their opponents' ancient structure. In this challenge, participants are to implement a model for Joint Slot and Intent Classification and to evaluate their results for toxicity language detection task via leaderboard.
Important Dates
- Leaderboard Challenges Due : 24 November, 2022
- Announcement of Winners: 28 November, 2022
- Camera-ready Abstract Due: 2 December, 2022
- TLD Workshop: 6 December, 2022 (11AM - 4PM, AWST (UTC + 8))
- Note: All deadlines are Anywhere on Earth (UTC - 12) time.
Organising Committee
- Workshop Chair: Ms. Jean Lee (The University of Sydney)
- Workshop Chair: Dr. Caren Han (The University of Western Australia and The University of Sydney)
- Leaderboard Chair: Mr. Kunze Wang (The University of Sydney)
- Student Chair: Mr. Joji Tenges (The University of Sydney)
- Advisory Committee: Dr. Henry Weld (The University of Sydney)
- Advisory Committee: Dr. Josiah Poon (The University of Sydney)
For any queries, send an email to jean.lee@sydney.edu.au